
 Fresh google verified proxies at your fingertips, whenever you need them. Proxy Raider is a super fast proxy scanner and scraper. It can find and verify hundreds if not thousands of proxies in a few minutes. To locate proxies it will scrape a list of pre-defined proxy sites (that can be extended freely), or use Google to search and scrape proxy IP’s. Once found it will verify if they work, how fast they are and what GEO location they have.
Fresh google verified proxies at your fingertips, whenever you need them. Proxy Raider is a super fast proxy scanner and scraper. It can find and verify hundreds if not thousands of proxies in a few minutes. To locate proxies it will scrape a list of pre-defined proxy sites (that can be extended freely), or use Google to search and scrape proxy IP’s. Once found it will verify if they work, how fast they are and what GEO location they have.
Main Features
- Scanning of class A to C IP ranges for an unlimited amount of ports
- Ability to scan each class C of a loaded IP list for additional proxies
- Unique randomized IP generator to scan for proxies
- Scraping of proxy IP’s from websites (proxy lists)
- Search Engine Scraping of sites that list proxies (and extraction + verification of IPs in one process)
- Heuristic scraping: de-obfuscation of proxy IP+port on websites that use javascript to hide the data
- Javascript unpacker (sandboxed)
- Verification of proxy lists against Google or custom sites
- Verification of private proxy lists that require authentication
- Ability to use internal proxies for scraping
- Proxy type (Anonym/Transparent) and speed analysis
- Internal GEO IP database
- Multithreads (unlimited)
- Pure sockets implementation, no insecure webbrowser controls
- Blacklist of IP ranges to avoid (mostly .gov and .mil)

Review from Softpedia:
“Proxies are used in a number of cases and for various reasons despite the fact that they can affect transfer speed and sometimes crash. Proxy Raider is a tool that allows you to scrape various websites in order to obtain an impressively large number of verified proxies which you can take advantage of.
A user-friendly interface that is well suited for everyone
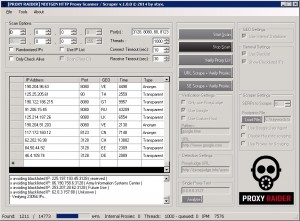
Proxy Raider displays an interface that is easy to make out even by the novice user, displaying all its main features and functions in the main window. You have quick access to scanning, proxy verifying and scraping. All that you need to run a successful proxy extraction is to load the website addresses into the application, click a button and wait until the task is finished. Depending on the number of websites you insert, the entire process can take a good couple of minutes but it will not end in disappointment. Proxy Raider can scan A to C IP ranges and generates a very large number of proxy addresses which are displayed in an easy to make out table that provides information for IP address, port, location, time and type.
A conglomeration of useful features
The application is capable of search engine scraping from websites that list proxies and extracts them for you in a simple manner. It also features heuristic scraping, proxy verification against Google, multithreading, and it also offers you the possibility to use internal proxies. In case there is an IP range that you don’t want to scan, the application allows you to add it to a blacklist in DB format which comes with the application.
Scrape a large number of websites and gather proxy servers
With the above to consider and a few more things to discover about it, Proxy Raider seems to be an appropriate tool for anyone who wants to obtain a considerable number of proxy addressees.
Detailed Feature explaination
1. Scanning
First of all you have a subnet scanner that can scan a complete class A (1.0.0.0 – 1.255.255.255) network, or class B and C. Simply select the range on top of the GUI and define the ports (comma separated or just a single port). You can also load a list of IP’s to scan and if you do that and select “scan class c’s”, the application will take every IP and scan its class C network for open proxies i.e.: 1.3.3.7 is the ip, the scanner would scan 1.3.3.0-255. If you select “randomized ip’s” the scanner will generate random ip’s and try to find proxies that way. It’s more of a luck game, but sometimes you find many proxies that you wouldn’t have otherwise.
2. Scraping
You have 2 modes here, first you can scrape a list of urls for proxy ips+ports (there is a list included already -> “freeproxy-sites.txt”). Just hit the “URL scrape” button and it will scrape all urls in the list and after its done, sort the found ip’s (remove duplicates), then runs the verification process. This is one of the things that makes this tool unique as these proxy sites try to obfuscate their ips/ports so scrapers can’t get them easily, thats why hrefer etc fails. However proxy raider has limited javascript support and can unpack many of these packer scripts to get the hidden data. A note on security: it does not use a webbrowser control to execute the javascript as that would put you at risk! It works with pure sockets and does only execute specific javascripts in a sandbox so you can’t get infected with anything! What it does basically -> it loads a unpacker for the packer used by for example samair.ru to hide their ip’s like this:
114.80.81.50>script type="text/javascript">
// >![CDATA[document.write(":"+v+y)// ]]>>/script>
So a scraper can’t get the port, only the IP. Well now you can scrape those sites too 😉 proxy raider has also workarounds for other tricks like base64(), urlencode(), ip2long(), css trickery
and hidden div’s to mask the ip/port can be circumvented in many cases! The second “SE scrape” option is almost the same, just that instead of providing a url list, it will scrape bing for sites that list proxies. In order to use it, you first have to load a footprints file. A good idea is to just take a handfull proxies that you scanned/scrapped lately and use those as footprint i.e. 123.5.6:3128 that way you usually find a lot of sites that list proxies and also forum posts and/or pastebin dumps of recent proxies. then select the amount of search engine result pages to scrape (usually between 3-20 is a good value, deppending on how fast you want results) you will end up with alot of ip’s and most will be dead, but usually you get a few thousand working ones. Once scraping urls via bing.com is finished, the scanner will do the same as above – scrape each url for proxy ips/ports, sort the found ones and then run the verification process. note that for the bing scraping process, the threads will be limited if you use too many, but unlock itself after that. so for the IP scraping and verification process the full thread amount will be utilized. If you “disable heuristic scraping”, the scan will be faster and require less cpu/memory, but will also find less ip’s as this is the function that will run the advanced de-obfuscation features explained earlier. Another option to “use google user agent” is available to get content from sites (mainly forums) that want you to register before accessing their content, but let google scrape their posts/threads. You can also scrape through proxies in case some sites ban your ip. to do this, simply tick the checkbox in the scraper settings “use proxies for scraping” and a load file dialog will apear. Now just select a working proxy list, thats it! note that these proxies won’t be verified before use, so make sure they work.
3. Verification
With this option you can load an existing proxy list and verify it. the format should be one entry line by line. For example:
123.4.5.6:8080
1.3.3.7:3128
…
You can also load files generated by proxy raider that look like: :::
4. Blacklist
There is a file included “blacklisted-ranges.db” you can open it in a text editor to view it. its simply a list of ranges that should be avoided to scan. its mostly government and military ranges that should better be ignored (even if there would be proxies, do you really want to relay your data through a gov box ?). Of course you can manually add ranges aswell.
Download
You can download a demo version with restricted features here: DEMO DOWNLOAD
A single license is $39 + Taxes one time and comes with free updates!
You can order your license here:
![]()